Do you want to just extract text from scanned PDF documents to Word files? Just by reading this article, you will get some ideas about how to extract plain text contents from common or scanned PDF document that has both texts and images.
To convert scanned PDF documents to plain text, you need a special application that can convert them to editable text with OCR function.To save your time, you can directly use EEPDF PDF to Word OCR Converter. It is specially designed to extract the plain text from common and scanned PDF document.
Now let me show you how to use it to extract the text contents from scanned PDF with the following example.

The above is a snapshot of the scanned PDF file.
1.Download EEPDF PDF to Word OCR Converter, then install it on your computer.
2. Add the above scanned PDF document into the application.
3.Choose the output layout.
Select the second option-Text only (No Images) in the drop-down list of “Output Options”. Then, the application will only convert the text contents in the PDF file and exclude the images in it.

4.Choose DOC or RTF as the target format.
In the “Output Formats” group box, either “DOC” or “RTF” can be checked as the target format. Since it is MS Word Document (*.DOC) by default, you can leave it alone if you want to convert the scanned PDF to DOC. But if you want to convert it to RTF, you need to check the radio box before Rich Text Format (*.RTF). Here, for instance, we select the second option.
5.Convert the scanned PDF to RTF.
Click Convert > select a proper folder in the pop-up “Save as” dialog box > click OK to export the RTF files.
The following is the extracted text from the above PDF file.
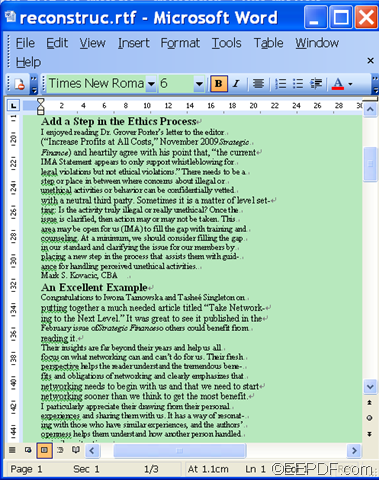
That’s how to extract plain texts from scanned PDF document to editable Word files.
You can click ![]() to try EEPDF PDF to Word OCR Converter by yourself.
to try EEPDF PDF to Word OCR Converter by yourself.
Hi
In this software after conversion can we edit in word document? how much cost for this software?
Hi, please check details on our website. Price is $59.95. You can use it free for tens of times, please have a try then if you have further question, please contact us again.