You can fulfill the process to extract text of specified pages from scanned PDF to XLS with OCR technology in Windows systems.
Please install a professional tool on your computer firstly: click here, you can get installer of EEPDF PDF to Excel OCR Converter, then you need to double click it so that installation of EEPDF PDF to Excel OCR Converter can be done successfully with setup wizard step by step.
Then, you should open this tool till its GUI interface is opened on your screen. And then, please do the followings to accomplish process to extract text of specified pages from scanned PDF to XLS:
1. Add scanned PDF file: click “Add PDF Files” > select scanned PDF file and hit “Open” in dialog box of “PDF to Excel”.
2. Set objective format as XLS: click radio of “MS Excel 2007 format (XLSX)” on GUI interface.
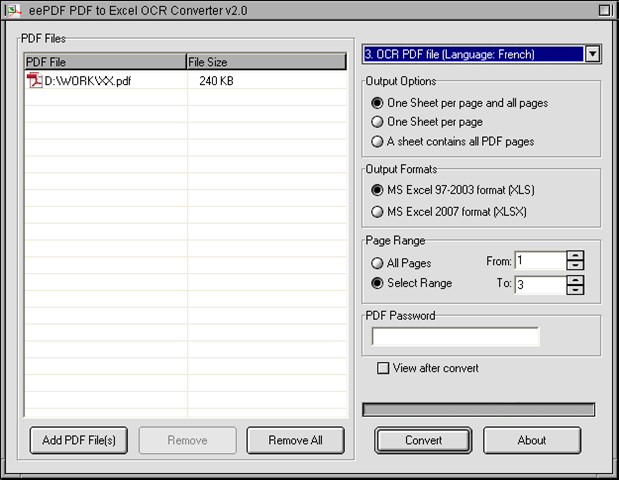
3. To extract text from scanned PDF, firstly, you need to figure out which language scanned PDF contains, then please select one of “OCR PDF file (Language:…)” on dropdown list of right-top corner of GUI interface, whose purpose is to make EEPDF PDF to Excel OCR Converter extract text of that language from scanned PDF file with OCR technology later. In addition, both of them are essential to extract text from scanned PDF file.
4. To set specified pages of scanned PDF file, please click radio of “Select Range” on GUI interface, then type page numbers in edit boxes of “From” and “To”. For instance, to get pages from 1 to 3 processed later, please type 1 and 3 in those edit boxes separately.
5. Finally, please click “Convert” button on GUI interface, besides selecting a targeting folder in dialog box of “Save As”, please click “Save” there, then EEPDF PDF to Excel OCR Converter can help you fulfill this process with OCR technology.
So after you understand the steps to extract text of specified pages from scanned PDF to XLS, for any doubts on it, please leave your comments here. And for more knowledge of EEPDF PDF to Excel OCR Converter, please visit official website of EEPDF PDF to Excel OCR Converter.